Why should archaeologists need to consider statistical methods and models? The answer is relatively simple, in that whenever features or attributes of an artefact are measured, or one is interested in creating a chronology, then numerical information is created and if the discipline is in the fortunate position of having a number of such artefacts (e.g. pots from a single site or several sites) or a series of dates, then the right tools are needed to summarise the information which has been collected and to capture and quantify any uncertainty. This short section will focus on how to ‘build a model and complete an analysis’, in the chronological context, before briefly reflecting on some of the classical statistical methods used in, for instance, seriation.
First, what is a statistical model? It is a conceptual description of the processes that generate the data we observe. The mathematical formulation of this conceptual description implies setting the corresponding equations, and defining the parameters (unknown quantities) that appear in these equations. Computationally, the model (estimate parameters) needs to be populated using data that has been observed or measured.
Calibration and chronology construction
The first and simplest example of a statistical model comes in 14C calibration where the process starts with calibrating a single measurement. The process of calibration converts a 14C age (in year BP) and its associated uncertainty to a calendar age with a derived uncertainty. The 14C age is derived from a measure of the 14C activity in the sample, assumed for most materials (the exception being aquatic or marine samples) to have been in equilibrium with the atmosphere at time of ‘life’.
Calibration of radiocarbon measurements requires knowledge of the levels of atmospheric radiocarbon in the past, captured in the internationally agreed calibration curves (Reimer et al. 2004, 2009, Bronk Ramsay et al. 2006). These curves are constructed from 14C measurements made on long series of known-age material including tree rings, corals and varved sediments of marine origin, etc. The IntCal Working Group continues to work on the development of a ratified update – and the next update is expected in 2012. Based, in the early years, on dendro-dated tree-rings and being limited to approximately 12,000 years, with the addition of other archives, the calibration curve is being extended and now is available to 50,000 years or more (with, however, some caveats).
As the available data for calibration increased in volume and improved in quality, there have been significant changes to the actual calibration method being used, moving from the very simple curve intersection approach to the much more complex probabilistic approach (often Bayesian) that takes account of uncertainties in both the dates and the actual curve.
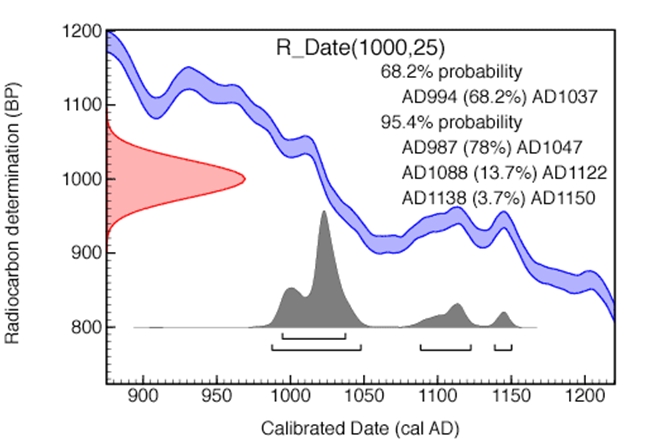
Downloaded from c14.arch.ox.ac.uk/embed.php ORAU May 2011
The statistical model begins here by describing a probability distribution for the 14C date and its uncertainty conditioned on its unknown ‘true’ calendar age (the model parameter). This distribution is most commonly the Normal or Gaussian distribution. The 14C distribution is then ‘compared’ to the calibration curve to identify the calendar time window most compatible with the observed 14C activity. The result is a range of possible (or plausible) calendar ages for the sample identified by the distribution curve on the calibrated date axis (see below for a graph downloaded from the OxCal web site).
The sophistication of calibration modelling has been aided by major developments in the calibration software. Nowadays, there are a number of calibration programs available for terrestrial samples and for marine samples, the most widely used being Calib, BCal and OxCal and which are easily downloadable from the web or run on-line. In addition there are a number of special purpose programmes such as as BPeat, BChron, and CaliBomb.
Statistical inference
a) simple questions concerning population parameters
Hypothesis testing and confidence intervals
Hypothesis or significance testing is a formal method of statistical inference. The hypotheses are framed in terms of population parameters (such as the population mean or average). On the basis of a set of archaeological samples drawn from the population of interest, a statistic is calculated (such as the sample average), the statistic is to the sample as the parameter is to the population. Knowledge of how the sample was drawn from the population and the value for the statistic allows one to generalise or infer the value of the parameter. In the hypothesis testing framework, it could, for example, be tested whether the population mean age (or Si concentration) is the same or different (summarized by the p-value) between two populations or confidence intervals (or plausible ranges) can be produced for the value of a population parameter or the difference in parameters.
b) questions concerning relationships
Correlation and regression
When there are several variables (measured on the same artifact), then a common investigation concerns the relationships between the two. Such a question of interest would be answered using a) correlation coefficients (Spearman or Pearson depending on distributional assumptions ) and b) if it is considered that the value of one variable (response) is in fact determined by the other (explanatory), then one might consider building a regression model. This latter type of modeling structure can also be extended to the situation where there are potentially many explanatory variables.
Multivariate data
There are a variety of techniques including clustering, principal components analysis and discriminant analysis, commonly described as multivariate techniques, since they are applied to data sets where there are many artefacts, and on each artefact, there are a number of variables measured. Each specimen whether it be a pottery shard, glass fragment, or coin will have a number of measurements made on it (eg metallurgical analysis, or shape (length, breadth etc) or decoration). Since the measurements are made on a single specimen, they are likely to be related, so in this sense, we have an extension from the bivariate (two variable- correlation) case to the multivariate (many variable case).
There are many questions which could have been asked and which will have influenced how the data were collected. Consider some of the most commonly asked questions:
c) Question: are there any groups and if so how many, and which objects belong to which groups?
Cluster analysis is used where the objects do not belong to known groups. Rather the purpose is to examine whether the objects tend to cluster into a small number of groups.
One objective of a study might be to identify groups of objects which are similar in terms of their characteristics (e.g. use or age). This requires the ability to detect patterns, and a scale on which to measure similarity in terms of the characteristics.
In clustering, the aim is to produce a picture of the grouping of the objects based on the dissimilarity matrix. The picture is known as the dendrogram, and like objects appear close together. There are many methods of producing a dendrogram, one of the methods begins by each individual object forming a cluster, then the two objects which are most alike are joined together and all the dissimilarities re-calculated, the smallest dissimilarity is then identified and these two objects (one of which may be the original two object group) joined together and so on until all the objects have ultimately been joined.
How is it decided how many groups or clusters exist?
Cluster analysis is an exploratory tool, so that there is no formal means of answering the question, how many clusters, and indeed the validity of any groupings so identified must be considered. There is no simple answer to these questions.
d) Question: what features identify known groups?
In discrimination, there is a set of objects that fall into known groups, and there are data from each of the objects. The aim of discrimination is to build a classification rule that may be applied to new objects in order to allocate them to the most appropriate group.
Suppose that study of 4 distinct contexts on a site, revealed from each a large hoard of pottery. Each pottery piece was analysed and measured for a number of attributes and the archaeologist was interested in finding out whether it was possible on the basis of the attributes to separate the pottery. This is a problem of discrimination, in that it is known that there are 4 groups and it is desired to find out what determines this classification.
One further point is that a number of misclassifications will be made. Obviously this number should be kept as small as possible. In linear discriminant analysis, linear functions of the variables are used to determine the classification, but there are also more general forms of discriminant analysis. There is a note of caution however, since there is a need to use a training set to identify the classification rule, but the same data should not then be used to assess the performance, unless the approach taken is modified by using cross-validation.
e) Question: can the problem be simplified (reduce the number of dimensions)?
Principal component analysis (PCA) is used where there are a number of different variables which are measured on each specimen and the aim is to reduce dimensionality and thus to find a smaller number of new variables that are uncorrelated and explain almost all of the variation of the original data. It is sometimes called an ordination technique. Thus PCA provides a transformation of the data in which a large percentage of the variation in a large number of variables is compressed into a smaller number of variables. It does not assume an underlying model, and is again used as a data descriptive or exploratory tool.
The new variables are combinations (linear) of the original variables which retain a large percentage of the original information contained in the full data set, and they are constructed to be uncorrelated. The key input to the analysis is either the correlation or covariance matrix. The underlying rationale is that if two variables possess some underlying common factor, then they should be highly correlated. Thus from studying the correlation matrix, the aim is to produce a new set of common variables which are themselves unrelated. One of the key pieces of output from a PCA is the cumulative proportion of variation explained, obviously high values for this based on small numbers of new variables, means that the reduction in dimensionality will be successful.
Compositional data
In some multivariate situations (eg such as major element composition), it is possible that the row sums are fixed (in this case say equal to 100%) and in this case, it is not possible to proceed as though the variables were independent, since to do so could result in incorrect inferences being made. One result of ignoring such constraints is that spurious correlations are found, which obviously interfere in the principal components or discrimination analysis. There has been some considerable debate concerning the most appropriate means to deal with such data, ranging from ignoring the problem, to creating a transformation of the data such that the variables are independent. This latter approach is often dealt with through using a log ratio transformation (Aitchison 1990).
Final comments
Especially in the context of chronology construction, statistical models are becoming increasingly complex, however one should always be mindful that statistical models make assumptions, which should be verified; that they should be fit for purpose, and that within the Bayesian context, extreme care should be taken in the specification of the prior. However that all said, statistical modelling has revolutionised much archaeological research and is an immensely valuable tool.